가우시안 혼합
- 생성된 모든 샘플은 하나의 클러스터 형성함
- 타원형
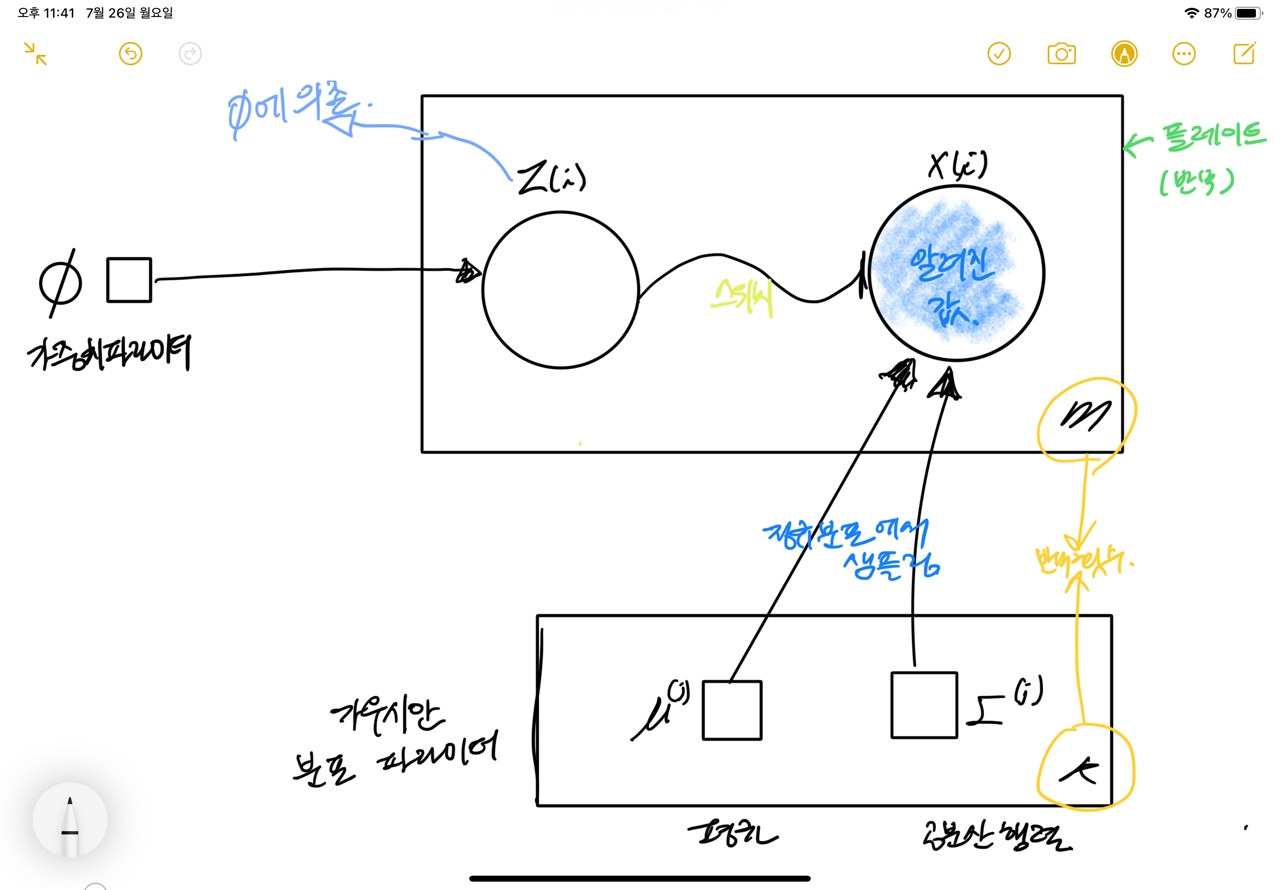
가우시안 혼합 모델의 그래프 모형 - 알려진 값 : 관측 변수
- 알려지지 않은 값 : 잠재 변수
- 기댓값-최대화 (EM)
- 클러스터 파라미터를 랜덤하게 초기화
- 수렴할 때까지 두 단계 반복
- 샘플을 클러스터에 할당 (기댓값 단계)
- 클러스터를 업데이트 (최대화 단계)
- 소프트 클러스터 할당 (각 군집과의 유사성으로 하나 이상의 군집에 속할 수 있는 거)
- predict_proba()사용
- 클러스터가 많거나 샘플이 적을 때는 최적의 솔루션으로 수렴하기 어렵
- 가우시안 혼합 모델 : 생성 모델
- 새로운 샘플을 만들 수 있음
- 주어진 위치에서 모델의 밀도 추정 가능
- score_sampels()
- 샘플이 주어지면 그 위치의 확률 밀도 함수(PDF)의 로그를 예측함
- 점수가 높을수록 밀도가 높음
- score_sampels()
1. 가우시안 혼합을 사용한 이상치 탐지
- 이상치 탐지 : 보통과 많이 다른 샘플을 감지하는 작업
가우시안 혼합 모델 :
- 이상치 포함해 모든 데이터에 맞추려고 한다.
- 이상치가 많으면 --> 정상치를 바라보는 시각이 편향됨
해결 방법
- 한 모델을 훈련
- 가장 크게 벗어난 이상치 제거
- 모델 다시 훈련
- 공분산
2. 클러스터 개수 선택
- k-평균처럼 이너셔나 실루엣 점수를 사용해 클러스터 개수를 선택 못함
- 클러스터가 타원형이거나 크기가 다를 때 안정적이지 않기 때문
- BIC, AIC : 이론적 정보 기준을 최소화하는 모델 찾음
- 학습할 파라미터가 많은 모델에게 벌칙
- 데이터에 잘 학습하는 모델에게 보상
3. 베이즈 가우시안 혼합 모델
베이즈 정리
- 데이터 x 관측하고 난 후 잠재 변수에 대한 확률 분포를 업데이트하는 방법을 설명함
- x가 주어졌을 때, z의 조건부 확률인 사후확률 분포를 계산함
P(z | X) = 사후 확률 = 가능도 * 사전 확률 / 증거 = P( X | z ) P(z) / P( X )
p(X)는 구하기 어렵다.
방법 :
- 변분 추론
- 증거 하한 ELBO 최대화
4. 이상치 탐지와 특이치 탐지를 위한 다른 알고리즘
- PCA
- Fast-MCD
- 데이터 셋 정제할 때 사용
- 가우시안 분포에서 생성되지 않은 이상치로 이 데이터셋이 오염되었다고 가정
- 가우시안 분포의 파라미터를 추정할 때 이상치로 의심되는 샘플 무시
- 타원형 잘 추정함
- 이상치를 잘 구분하도록 돕는다
- 데이터 셋 정제할 때 사용
- 아이솔레이션 포레스트
- 고차원 데이터셋에서
- 무작위로 성장한 결정트리로 구성된 랜덤 포레스트 만듦
- 각 노드에서 특성을 랜덤하게 선택
- 랜덤한 임곗값을 고름
- 데이터셋을 둘로 나눔
- 모든 샘플이 다른 샘플과 격리될 때까지 진행됨
- LOF
- 이상치 탐지에 좋음
- 주위의 밀도와 이웃 주위의 밀도 비교함
- one-class SVM
- 특이치 탐지
- 고차원 데이터셋에 잘 작동함
- 원본 공간으로부터 고차원 공간에 있는 샘플 분리함
- 원본 공간에서는 모든 샘플을 둘러싼 작은 영역을 찾음
- 새로운 샘플이 이 공간에 놓이지 않으면 이상치임
'Hand-On Machine Learning' 카테고리의 다른 글
| [핸즈온 머신러닝] 2장 (0) | 2021.07.22 |
|---|