import os
import tarfile
import urllib
import pandas as pd
housing = pd.read_csv('./housing.csv')
housing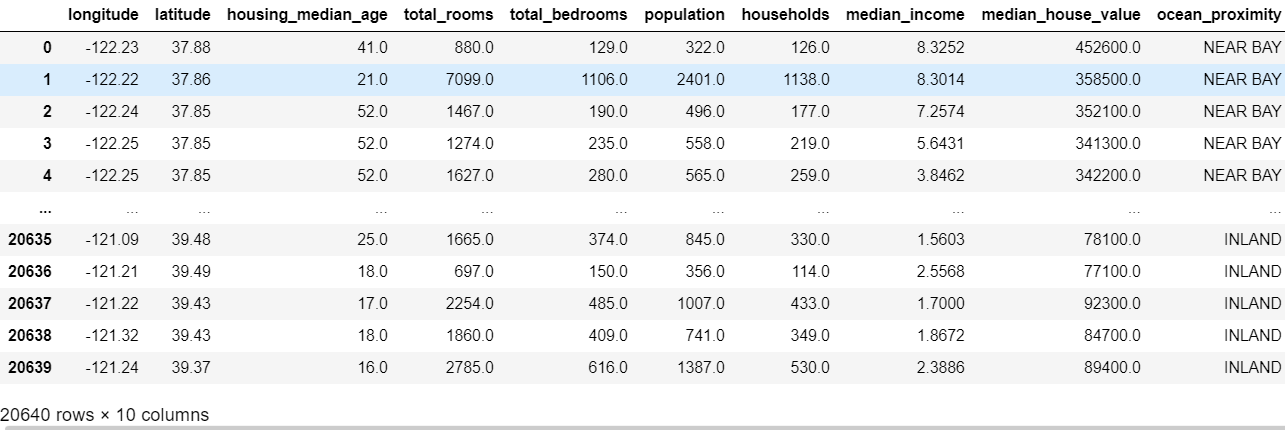
결측치 확인
housing.info()
ocean_proximity가 어떤 카테고리가 있고, 각 카테고리마다 얼마나 많은 구역 있는지 확인
housing["ocean_proximity"].value_counts()
bescribe()
- 널 값 제외.
- 숫자형 특성의 요약 정보 보여줌
- std : 값이 퍼져 있는 정보 측정 (표준 편차)
- 백분위 수
- latitude의 25%는 33.93보다 작음
housing.describe()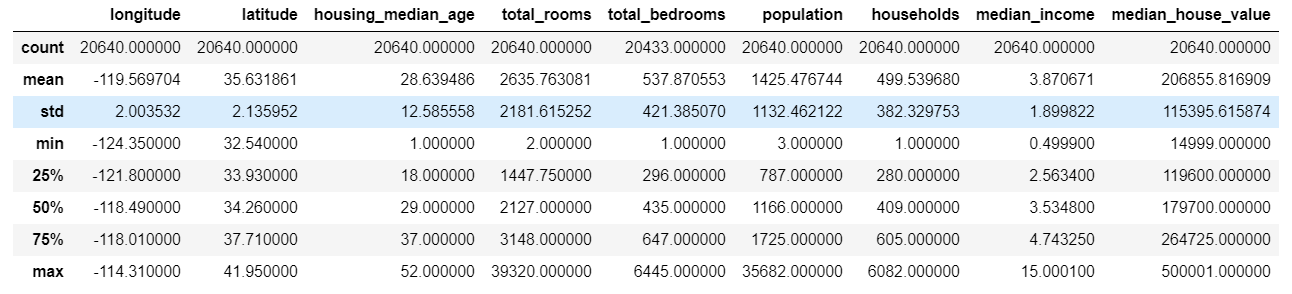
히스토그램 그려보기
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins = 50, figsize = (20,15))
plt.show()- %matplotlib : 맷플롯립이 주피터 자체의 백엔드 사용하게
테스트 세트 만들어보기
from zlib import crc32
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_ : test_set_check(id, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]housing_with_id = housing.reset_index()
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")→ 해시값을 계산하여 해시 최대값의 20%보다 작거나 같은 샘플만 테스트 세트로 보낼 수 있음
사이킷런
train_test_split
- 난수 초깃값을 지정 가능 - random_state
- 행의 개수가 같은 여러 개의 데이터셋을 넘겨서 같은 인덱스를 기반으로 나누기 가능
from sklearn.model_selection import train_test_splittrain_set, test_set = train_test_split(housing, test_size = 0.2, random_state = 42)
계층적 샘플링
- 카테고리 5개 가진 소득 카테고리 특성
- bin - 카테고리 범위
-
housing["income_cat"] = pd.cut(housing["median_income"], bins = [0.,1.5,3.0,4.5,6.,np.inf], labels = [1,2,3,4,5])
'Hand-On Machine Learning' 카테고리의 다른 글
| [9장] 비지도 학습_가우시안 혼합 (0) | 2021.07.27 |
|---|